The Frugal Analyst
Optimising the costs of my Discount Analyst agent
Discount Analyst
Published: Sat, 21 Mar 2026

Abstract
In this blog, I explore empirically evaluating different cost-cutting methods in my stock valuation agent. The code for this can be found here.
Introduction
After implementing the MVP of the Discount Analyst, which values stocks using DCF analysis, I realised that the agent is only going to get more and more expensive as I had more steps to it and enhance it with more tools and features.
I decided to investigate how to optimise the costs of my agent now, so that all of my future experimentation and inference would be cheaper.
Recap
In my previous blog, I introduced Discount Analyst: my stock valuing agent. In this blog we will optimise the cost of this agent. Before we start doing that, here is a recap of my agentic investing workflow.
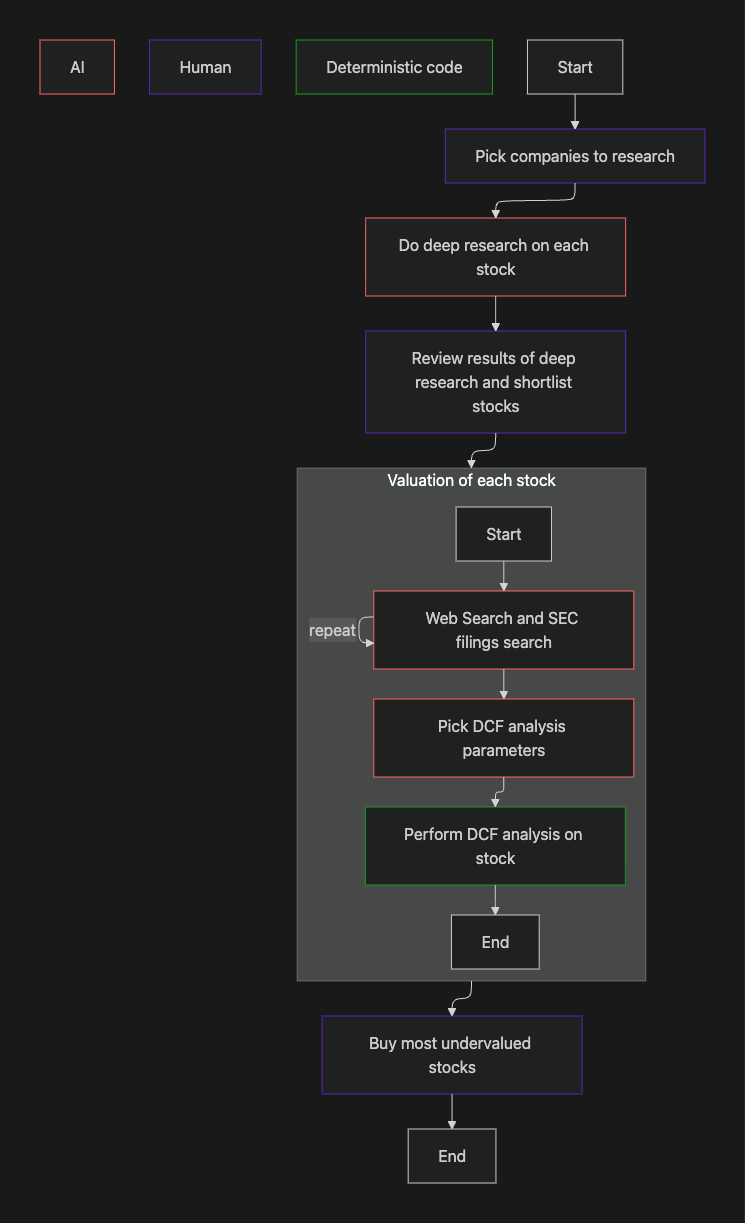
My agentic investing workflow from the end of my last blog.
If you need a better recap, you can find the original blog here.
Model Choices
Comparing Costs
To get a rough idea of inference costs, I decided to run my agent with a few different stocks and measure the cost.
Batch processing on LLM APIs is a specific service tier where your request is not serviced immediately, but is instead queued to be processed at some time (usually up to a day later) when the server has spare compute available. Batch processing saves a lot of money, but unfortunately, it doesn’t really work for agentic mutli-turn conversations due to the massive up to 24hr time delay between turns, so I decided to use standard tier (on-demand processing) and flex tier (a tier unique to OpenAI that is on-demand processing, but with higher latency than their standard tier).
Amazon
I ran the discount analyst script on Amazon, a growth stock, with all models with cache enabled and disabled on the Claude models. For the Claude models the cache was always enabled for tool calls and system instructions, but I had it disabled for messages, so I wanted to test whether enabling this on messages would give me significant savings or speedup. Tool calls and system instructions are shared between conversations, so the caching benefit is more obvious there. Prompt caching on messages saves money on multi-turn conversations such as inference that involves tool use because each turn requires the conversation history to be sent to the API again. Writing tokens to cache costs more than not doing so, but reading cached tokens costs less than reading non-cached tokens, so your conversation needs read enough tokens from cache to outweigh the added cost of writing these tokens to cache to make prompt caching worth it. You can read more about how prompt caching (also known as KV caching here).
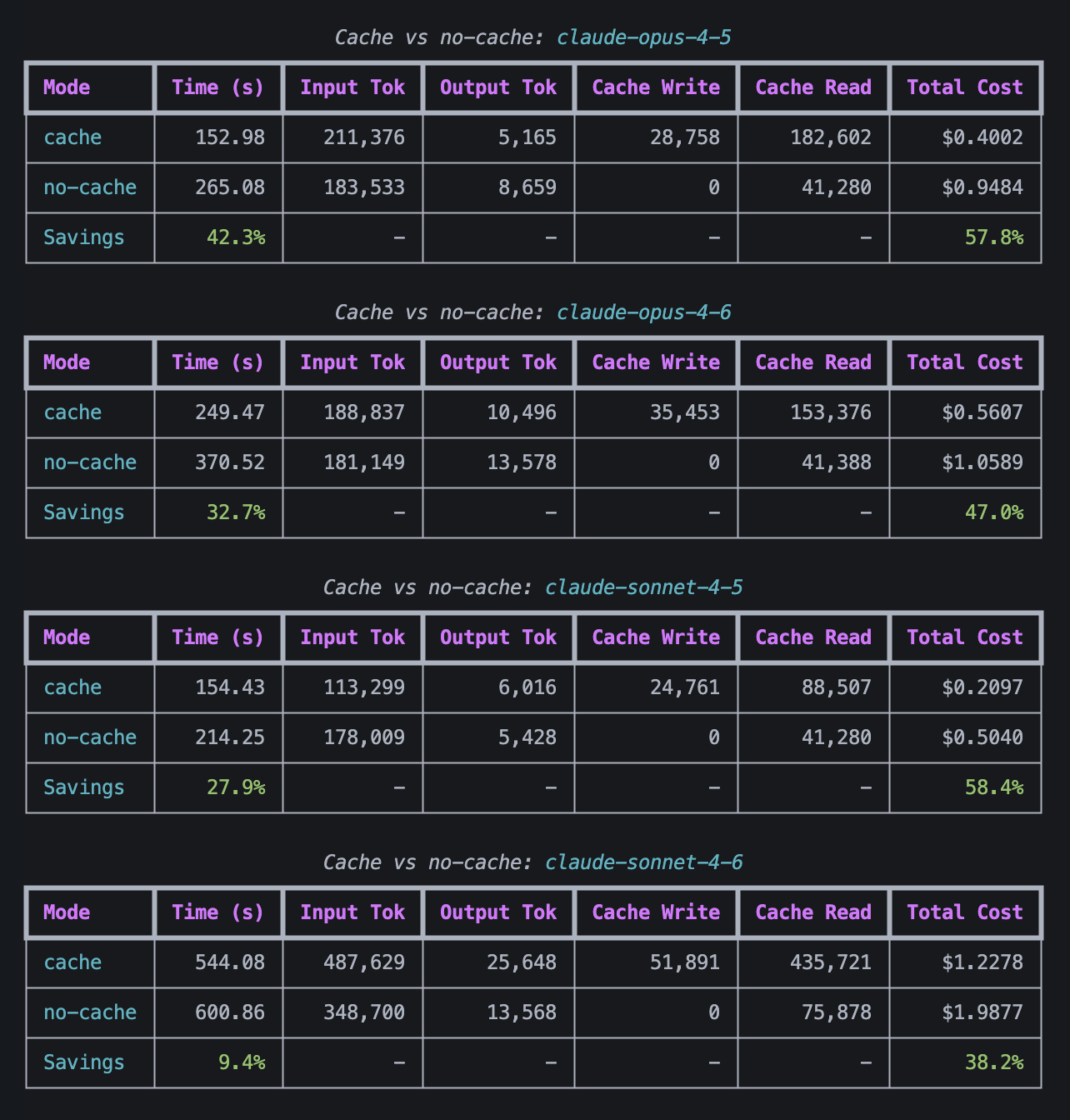
The cost when caching agent/user messages vs not caching agent/user messages when valuing AMZN.
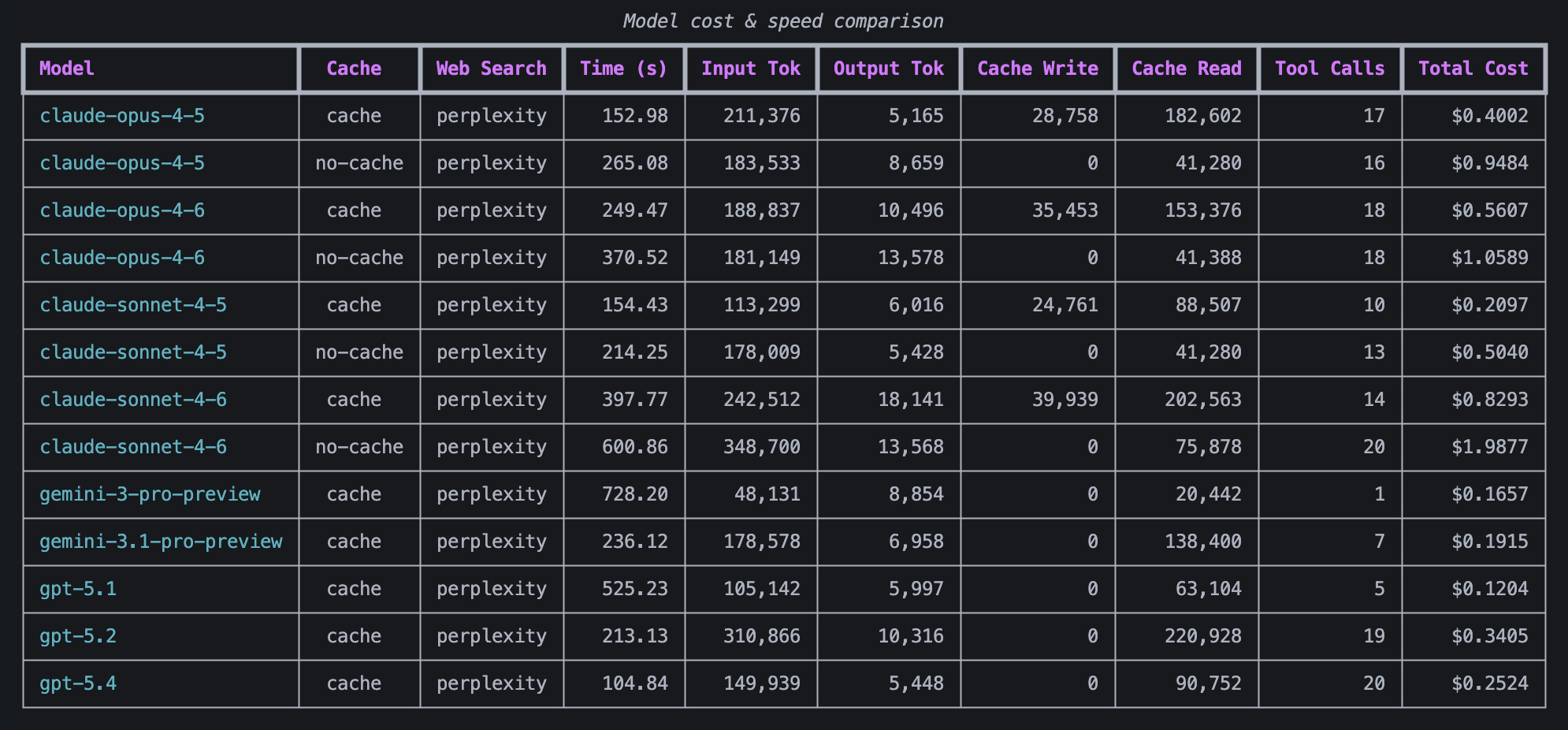
The cost and time taken for each model to value AMZN.
Key observations:
- Enabling caching on messages significantly sped up inference (by up to 40%) and reduced costs (by up to 60%).
- The cheapest models were Sonnet 4.5 (with cached messages), gemini 3 pro-preview, gemini 3.1 pro-preview, and GPT 5.1, but this is misleading as all of these used ten or less tool calls, making me suspicious that they did not adequately research the stock.
FDS
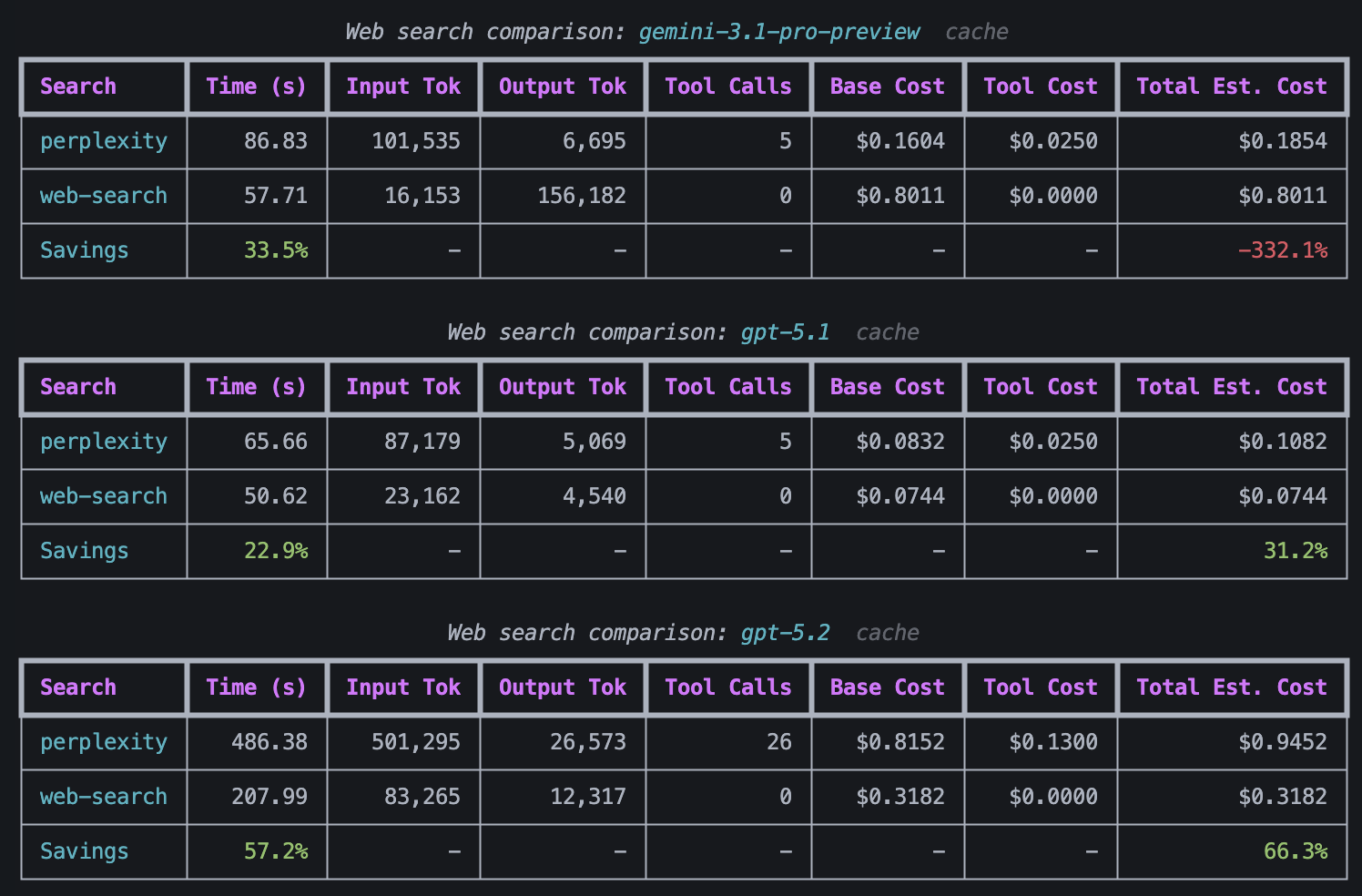
To confirm whether this was simply random chance, I decided to run this test again with FDS, a value stock, but this time, caching was turned on for all Anthropic models and I ran FDS with perplexity enabled but the built-in web search disabled and with perplexity disabled but the built-in web search enabled. I wanted to see whether it was cheaper to use Perplexity or the built-in web search.
Perplexity costs $5 per 1000 requests + model input/output token costs, but the token costs are so negligible that I did not include them in my comparison.
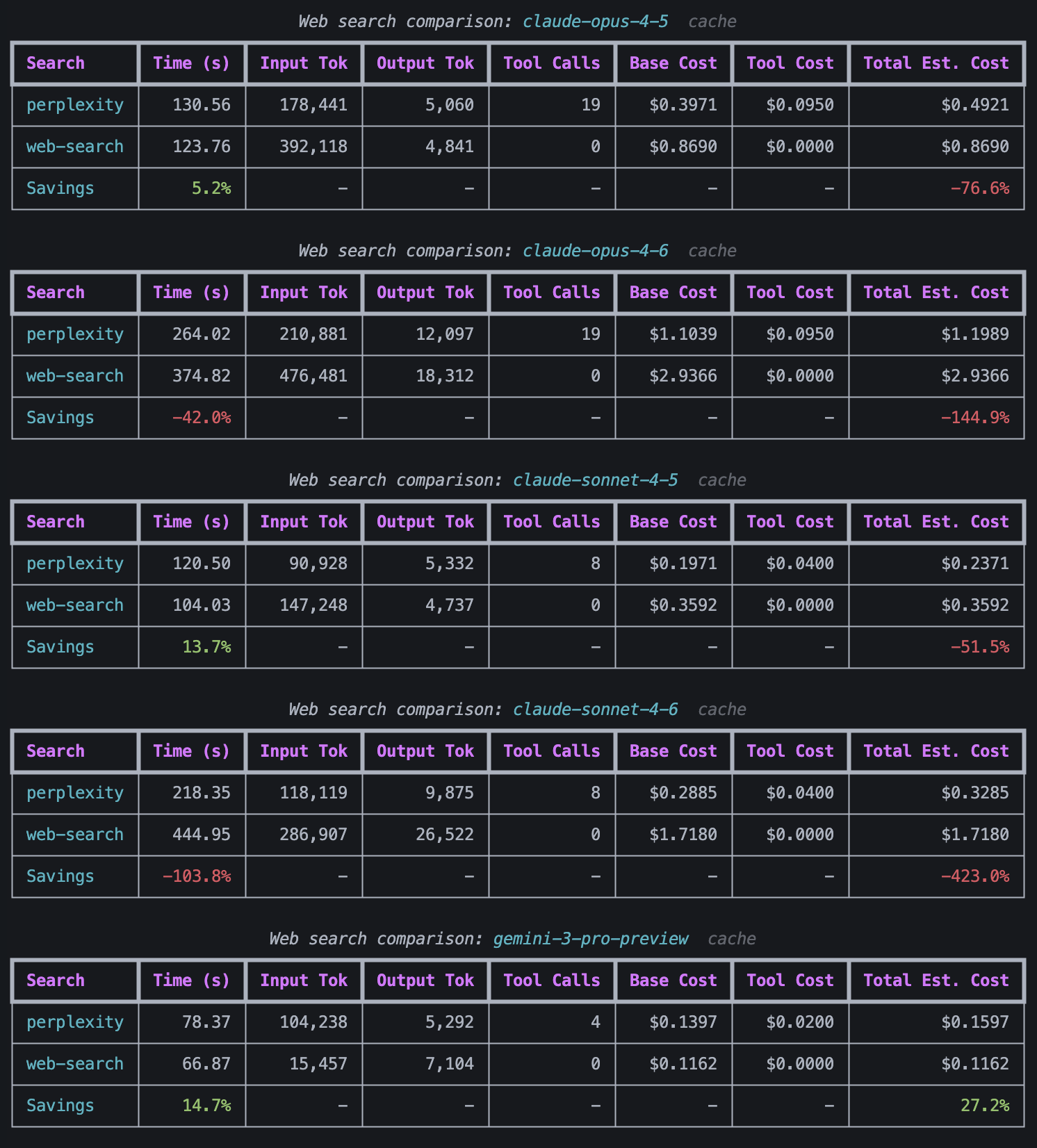
A comparison of the cost of valuation when using web search compared to using Perplexity.
Further comparison of the cost of valuation when using web search compared to using Perplexity.
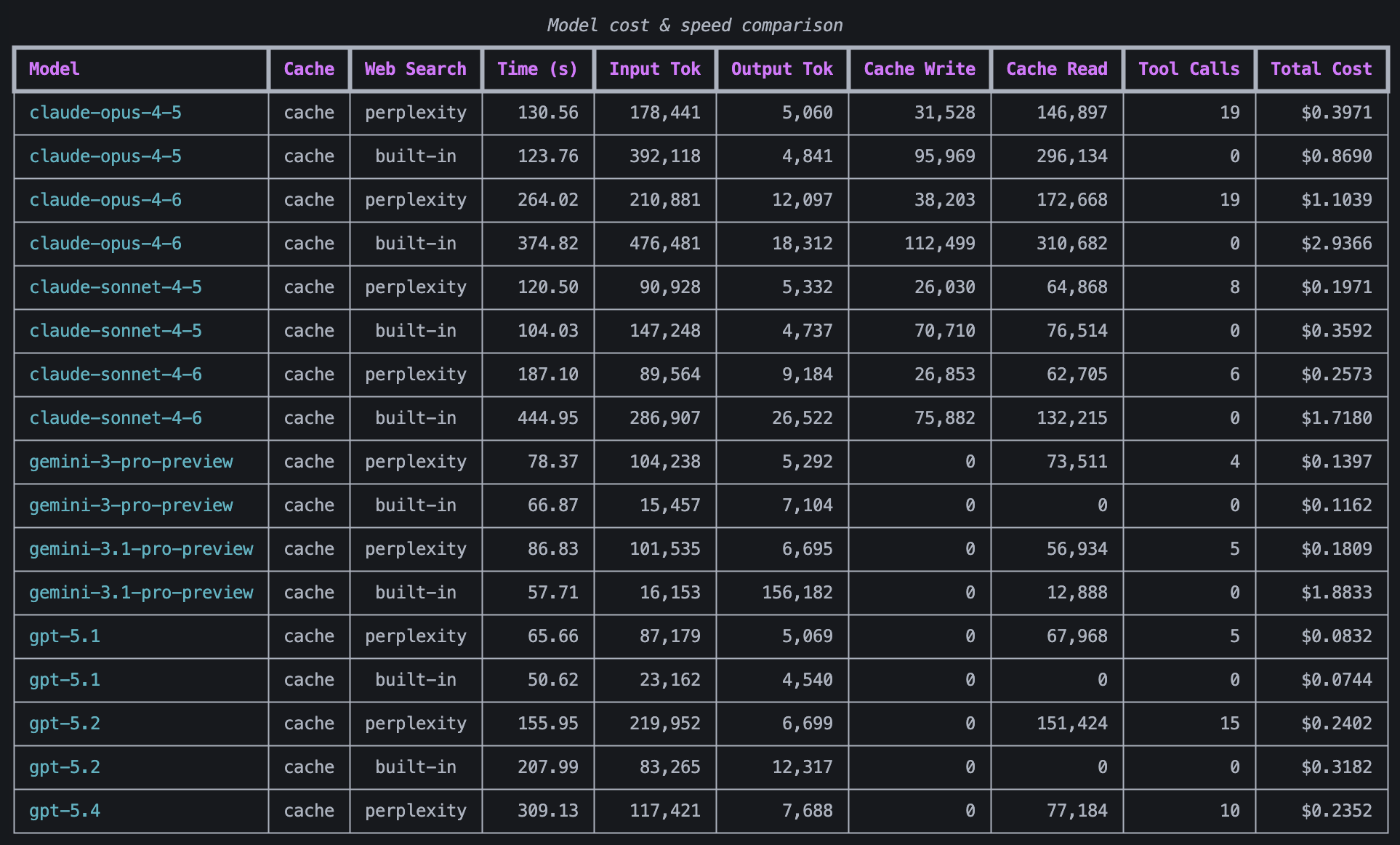
The cost and time taken for each model to value FDS.
GPT 5.4 is missing from the web search comparison tables because GPT 5.4 came out after I ran this test and when I tried running GPT 5.4 with web search, I kept getting rate limit errors. I am not sure why I got the rate limit errors for GPT 5.4, but not GPT 5.2 or GPT 5.1, but I didn't have time to debug it.
An interesting observation that can be made from this data is that the cheaper models like GPT 5.1, GPT 5.2, and Gemini 3 pro preview saved money by doing the web search themselves, whereas the more expensive models like Gemini 3.1 pro preview and the Claude models were cheaper when they offloaded the web searching to Perplexity.
I reviewed the logs and interestingly, I caught GPT 5.2 using the built-in web search to search ‘calculator: 201.71*37615000.’ I won’t implement it in this blog, but I clearly need to build a tool to allow my agents to calculate things. It's always worth reading the logs to ensure your agents are behaving correctly.
Key observations:
- Perplexity is cheaper than using web search for every model apart from Gemini 3 pro preview, GPT 5.1, and GPT 5.2.
- The cheapest models were: Claude Sonnet 4.5 (with Perplexity), Claude Sonnet 4.6 (with Perplexity), Gemini 3 Pro-Preview (with Perplexity), Gemini 3 Pro-Preview (with built-in web search), Gemini 3.1 Pro-Preview (with Perplexity), GPT 5.1 (with Perplexity), and GPT 5.1 (with built-in web search).
Meta
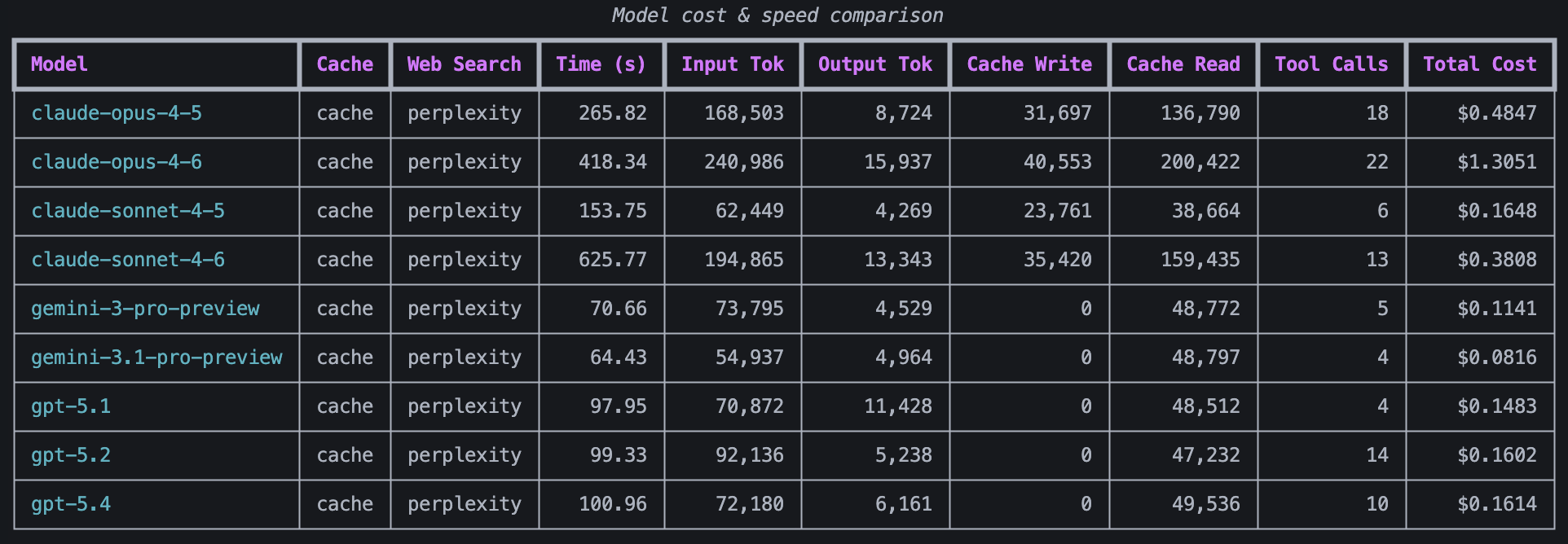
I decided to do one more test run before finding the average. I decided to use Perplexity for these tests because the agent runs were generally cheaper when I used Perplexity and I wanted to only test the difference in model inference costs, not web search costs.
Key observations:
- The cheapest models were Gemini 3.1 pro preview, Gemini 3 pro preview, GPT 5.1, GPT 5.2, GPT 5.4, and Claude Sonnet 4.5, which roughly aligns with the previous test runs.
Model Comparison
I then compared the cost of all of the models across all three stocks. For each of the AMZN Claude model costs, I used the cost when using message caching. For each of the FDS costs, I used the cost when using Perplexity. Additionally, for the rank on the Vals AI benchmarks, I ranked them while ignoring non-listed models
| AMZN Growth Stock | FDS Value Stock | META Growth Stock | Average | |||||
|---|---|---|---|---|---|---|---|---|
| Cost | Tool Calls made | Cost | Tool Calls made | Cost | Tool Calls made | Cost per test | Tool Calls Made | |
| Model | Value (USD) | Value | Value (USD) | Value | Value (USD) | Value | Value (USD) | |
| Claude Opus 4.6 (thinking) | 0.5607 | 18 | 1.1039 | 19 | 1.3051 | 22 | 0.9899 | 19.66 |
| Claude Opus 4.5 (thinking) | 0.4002 | 17 | 0.3971 | 19 | 0.4847 | 18 | 0.4273 | 18 |
| Claude Sonnet 4.6 | 0.8293 | 21 | 0.2885 | 8 | 0.3808 | 13 | 0.4995 | 14 |
| Claude Sonnet 4.5 (Thinking) | 0.2097 | 10 | 0.1971 | 8 | 0.1648 | 6 | 0.1905 | 8 |
| Gemini 3.1 pro-preview | 0.2382 | 9 | 0.1604 | 5 | 0.0816 | 4 | 0.1601 | 6 |
| Gemini 3 pro-preview | 0.1657 | 1 | 0.1397 | 4 | 0.1141 | 5 | 0.1398 | 3.33 |
| GPT 5.4 | 0.2524 | 20 | 0.2352 | 10 | 0.1614 | 10 | 0.2163 | 13.33 |
| GPT 5.2 | 0.4842 | 30 | 0.8152 | 26 | 0.1602 | 14 | 0.4865 | 23.33 |
| GPT 5.1 | 0.1204 | 5 | 0.0832 | 5 | 0.1483 | 4 | 0.1173 | 4.66 |
Interestingly, Claude Sonnet 4.5, Gemini 3.1 pro-preview, Gemini 3 pro-preview, and GPT 5.1 made very few tool calls compared to the other models. The available tools were the Perplexity web search and SEC filings search tool, so I was concerned that these models were not thorough enough in their research.
Comparison With 3rd Party Benchmarks
Model Leaderboard
My sample of 3 test cases was clearly not a very robust sample size, so I decided to use Vals AI’s finance Agent v1.1 benchmark to inform my model choice as it evaluates the same task that the discount analyst currently handles.
Benchmark methodology (from the benchmark page):
The finance industry comprises a wide array of tasks, but through consultation with experts at banks and hedge funds, we identified one core task shared across nearly all financial analyst workflows: performing research on the SEC filings of public companies. This task —while time-consuming— is foundational to activities such as equity research, credit analysis, and investment due diligence. We collaborated with industry experts to define a question taxonomy, write and review 537 benchmark questions.
The AI agents were evaluated in an environment where they had access to tools sufficient to produce an accurate response. This included an EDGAR search interface via the SEC_API, Google search, a document parser (ParseHTML) for loading and chunking large filings, and a retrieval tool (RetrieveInformation) that enabled targeted questioning over extracted text. The human experts did not make use of any additional tools when writing and answering their questions. See the full harness here.
Our primary evaluation metric was final answer accuracy (see the GAIA benchmark). We also recorded latency, tool utilization patterns, and associated computational cost to provide a fuller picture of agent efficiency and practical viability. Together, these components form a rigorous and domain-specific evaluation framework for agentic performance in finance, advancing the field’s ability to measure and rely on AI in high-stakes settings.
Vals.ai Finance Agent v1.1 benchmark leaderboard (last updated 17th March 2026):
| Rank | Model | Accuracy | Cost / Test |
|---|---|---|---|
| 1 | Claude Sonnet 4.6 | 63.33% | $1.44 |
| 2 | Claude Opus 4.6 (thinking) | 60.05% | $1.11 |
| 3 | Gemini 3.1 pro-preview | 59.72% | $0.87 |
| 4 | Claude Opus 4.5 (thinking) | 58.81% | $1.50 |
| 5 | GPT 5.2 | 58.53% | $0.98 |
| 6 | GPT 5.4 | 57.15% | $1.41 |
| 7 | GPT 5.1 | 55.31% | $0.47 |
| 8 | Gemini 3 pro | 55.15% | $0.56 |
| 9 | Claude Sonnet 4.5 (Thinking) | 54.50% | $1.10 |
Vals AI also state that 'The dataset is divided into three parts: Public Validation (50 open-source samples), Private Validation (150 samples available for license), and Test (337 samples).'
To compare the models, I also decided to also add the overall score from https://www.vals.ai/benchmarks/vals_index to measure the general intelligence of the models. While knowing a lot about finance is helpful, having a lot of general knowledge is equally important to ensure that the model understands and can reason about the nuances of the stocks it is researching.
| Vals Index | Finance Agent v1.1 | |||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Cost per test | Accuracy | Cost per test | |||||
| Model | Value | Rank | Value (USD) | Rank | Value | Rank | Value (USD) | Rank |
| Claude Opus 4.6 (thinking) | 66.06% | 2 | 1.00 | 9 | 60.05% | 2 | 1.11 | 6 |
| Claude Opus 4.5 (thinking) | 63.11% | 6 | 0.98 | 8 | 58.81% | 4 | 1.50 | 9 |
| Claude Sonnet 4.6 | 66.82% | 1 | 0.78 | 6.5 | 63.33% | 1 | 1.44 | 8 |
| Claude Sonnet 4.5 (Thinking) | 60.19% | 8 | 0.76 | 5 | 54.50% | 8 | 1.10 | 5 |
| Gemini 3.1 pro-preview | 64.86% | 3 | 0.57 | 3 | 59.72% | 3 | 0.87 | 3 |
| Gemini 3 pro-preview | 61.44% | 7 | 0.34 | 2 | 55.15% | 9 | 0.56 | 2 |
| GPT 5.4 | 64.59% | 4 | 0.71 | 4 | 57.15% | 6 | 1.41 | 7 |
| GPT 5.2 | 64.11% | 5 | 0.78 | 6.5 | 58.53% | 5 | 0.98 | 4 |
| GPT 5.1 | 60.93% | 9 | 0.28 | 1 | 55.31% | 7 | 0.47 | 1 |
Multi-Objective Optimisation of Accuracy and Cost
I plotted these data points with a Pareto frontier, the frontier of a multi-objective optimisation problem where at every point, a tradeoff must be made in one objective to achieve a better result in another objective. For example, Gemini 3 pro preview is Pareto optimal for the Vals Index because choosing a cheaper model yields a worse accuracy and choosing a more accurate model result yields a higher cost. On the other hand, it is not Pareto optimal in the Finance Agent v1.1 evaluation set as GPT 5.1 achieves a higher accuracy with a lower cost (i.e., there is no tradeoff between objectives).
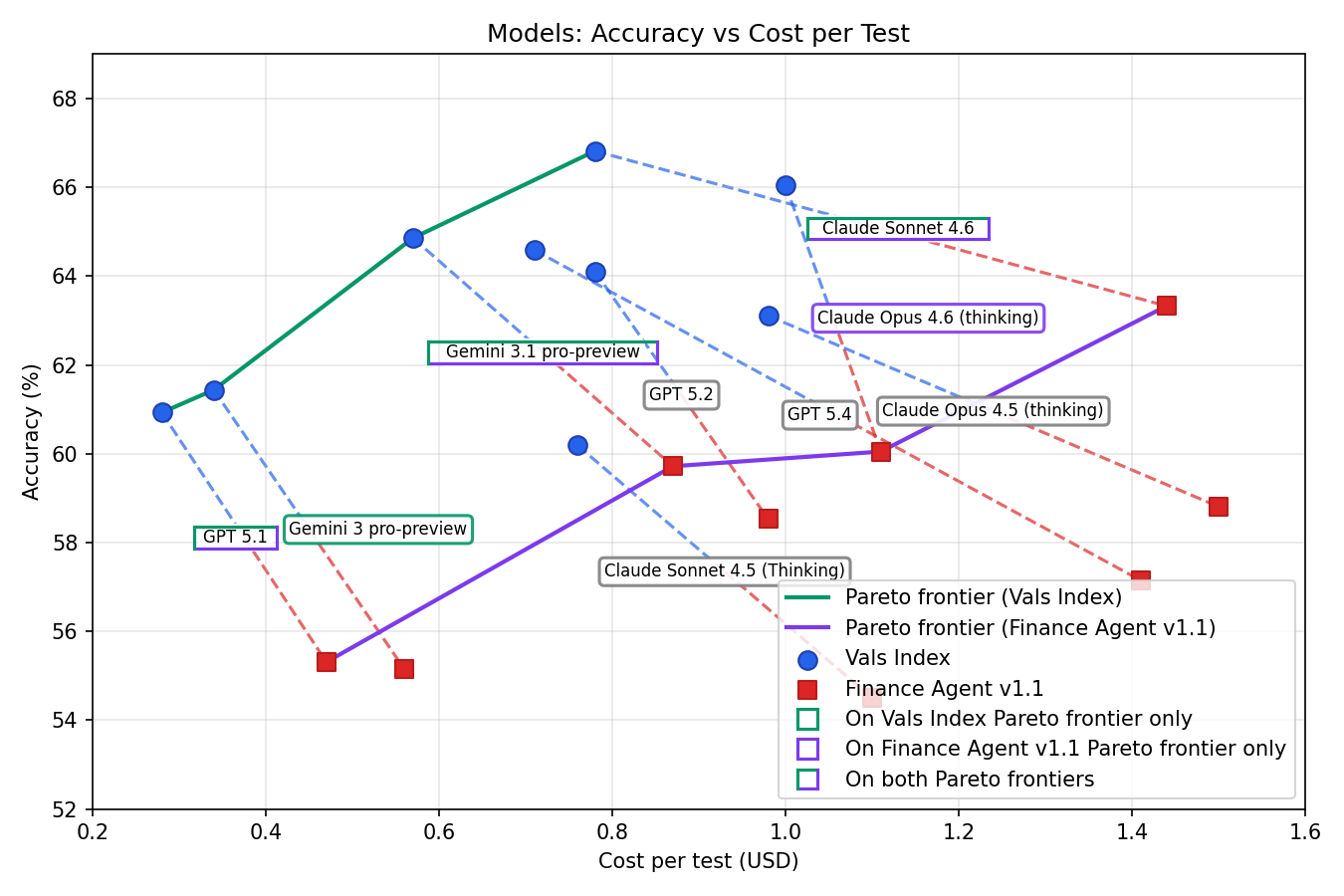
A scatter plot showing the Pareto frontiers that optimise accuracy and cost across all models on both datasets.
Some clear takeaways from the graph are that Claude Sonnet 4.5, Claude Opus 4.5, GPT 5.2, and GPT 5.4 do not fall on the Pareto frontier of either evaluation set, so they should not be chosen.
One thing that this graph misses is that OpenAI offers a flex tier API, which offers slightly slower responses for half the price. I assume the Vals AI researchers used the full-price API, so introducing the half-price API changes the results significantly.
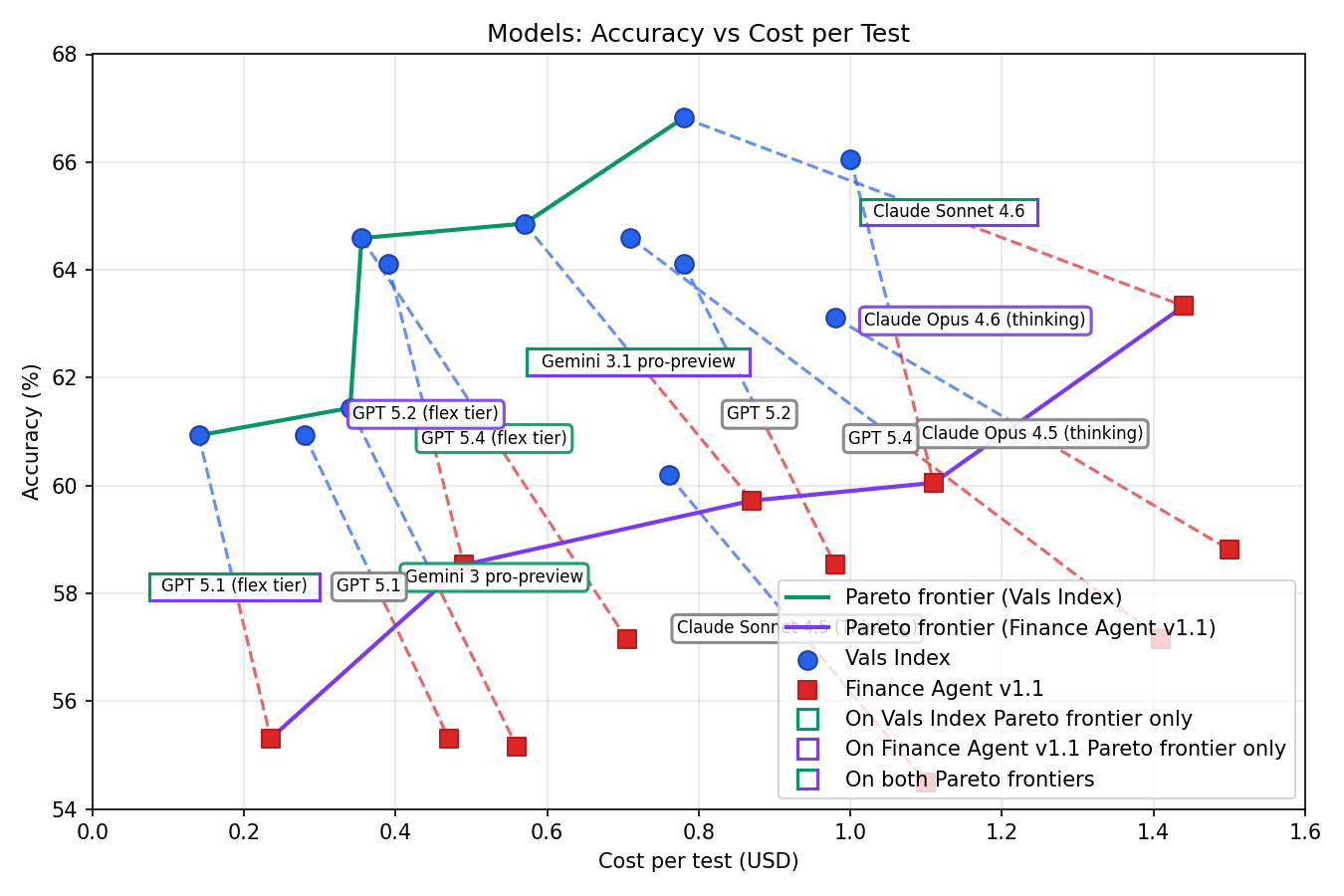
A scatter plot showing the Pareto frontiers that optimise accuracy and cost across all models on both datasets, but this time, including half-price flex-tier variants of the OpenAI models.
GPT 5.1 is still on both Pareto frontiers because it’s the cheapest model, but GPT 5.2 and GPT 5.4 entered the Pareto frontier because they became cheaper.
I decided to use GPT 5.1 as it was the cheapest ‘good enough’ model. To get a significant improvement in accuracy over GPT 5.1, a model that is 2-3x more expensive like GPT 5.2 (flex tier) or GPT 5.4 (flex tier) would need to used.
Sonnet 4.6 would provide a massive increase in accuracy, being best in class overall and in the Finance Agent benchmark, but I think I can make far greater gains in accuracy for the same price by enhancing my stock-picking workflow instead.
In my 3-stock sample, I noticed that GPT 5.1 used significantly less tool calls than the other models, which concerned me. Fortunately, the Vals AI Finance Agent benchmark shows it on average using a number of tool calls similar to other top-performing models, so this shouldn’t be an issue.
<u>).</u>](https://firebasestorage.googleapis.com/v0/b/bytes-and-nibbles.appspot.com/o/images%2Fbytes%2FbodyImages%2Fvals_ai_tool_calls.png?alt=media&token=04fae572-ef63-4ca2-a5e5-699ed1cd2c8c)
The tool calls made in the Vals AI Finance Agent v1.1 benchmark. Adapted from [Vals AI Finance Agent v1.1 benchmark](<u>https://www.vals.ai/benchmarks/finance_agent</u><u>).</u>
Promotions
After running my experiments, I was shocked when I opened my Google Cloud billing dashboard and found this:

Free Google Cloud credits from Google.
It turns out that when you start a Google Cloud free trial, you get ‘$300 in free Welcome credit which is valid for 90 days’ (see Google Cloud's signup FAQs for details).
OpenAI also offers 250M free tokens per day if you allow OpenAI to harvest all of your data (see their article on it).
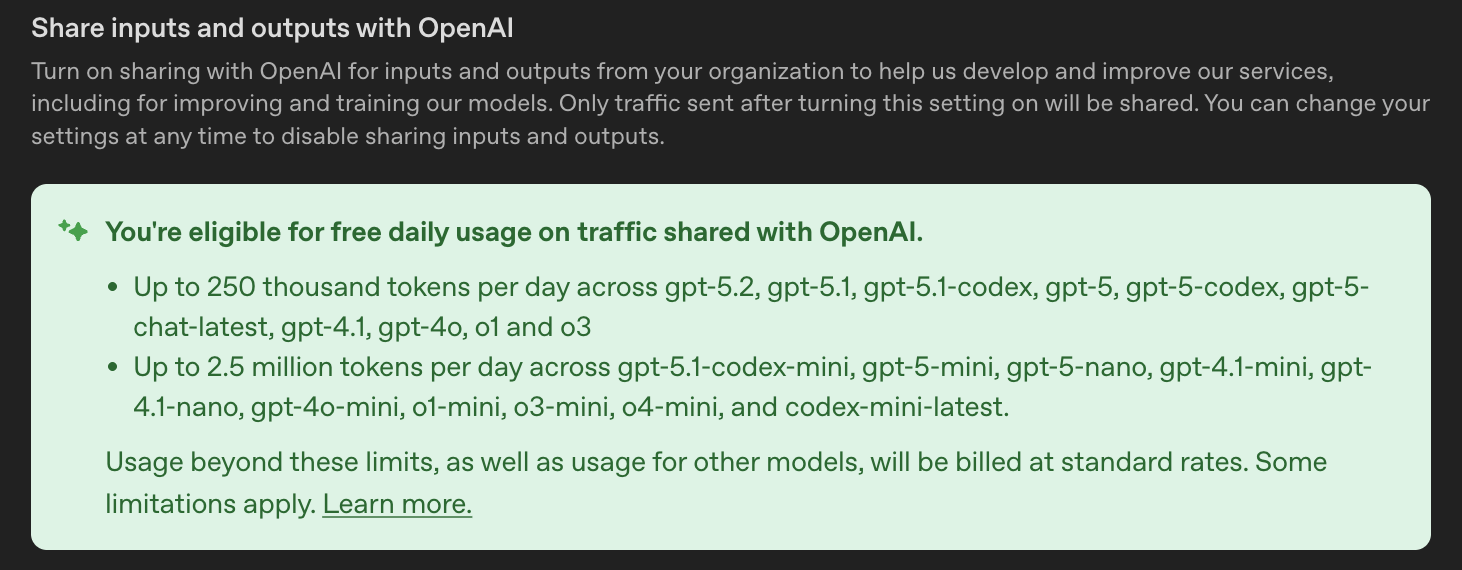
The banner in the OpenAI platform site explaining the free token deal.
This makes GPT 5.1 even cheaper to run, which further cements my choice.
Formalising a Conviction List
The New Flow
As I alluded to earlier in this blog, I plan to improve accuracy of my stock-picking agent by enhancing its workflow.
DCF analysis is incredibly sensitive to small changes in its parameters, so I decided to add a final step where for each stock analysed, I give an AI the deep research report and the results of the DCF analysis, and ask it to categorise the stock into: STRONG BUY, BUY, HOLD, SELL, or STRONG SELL.
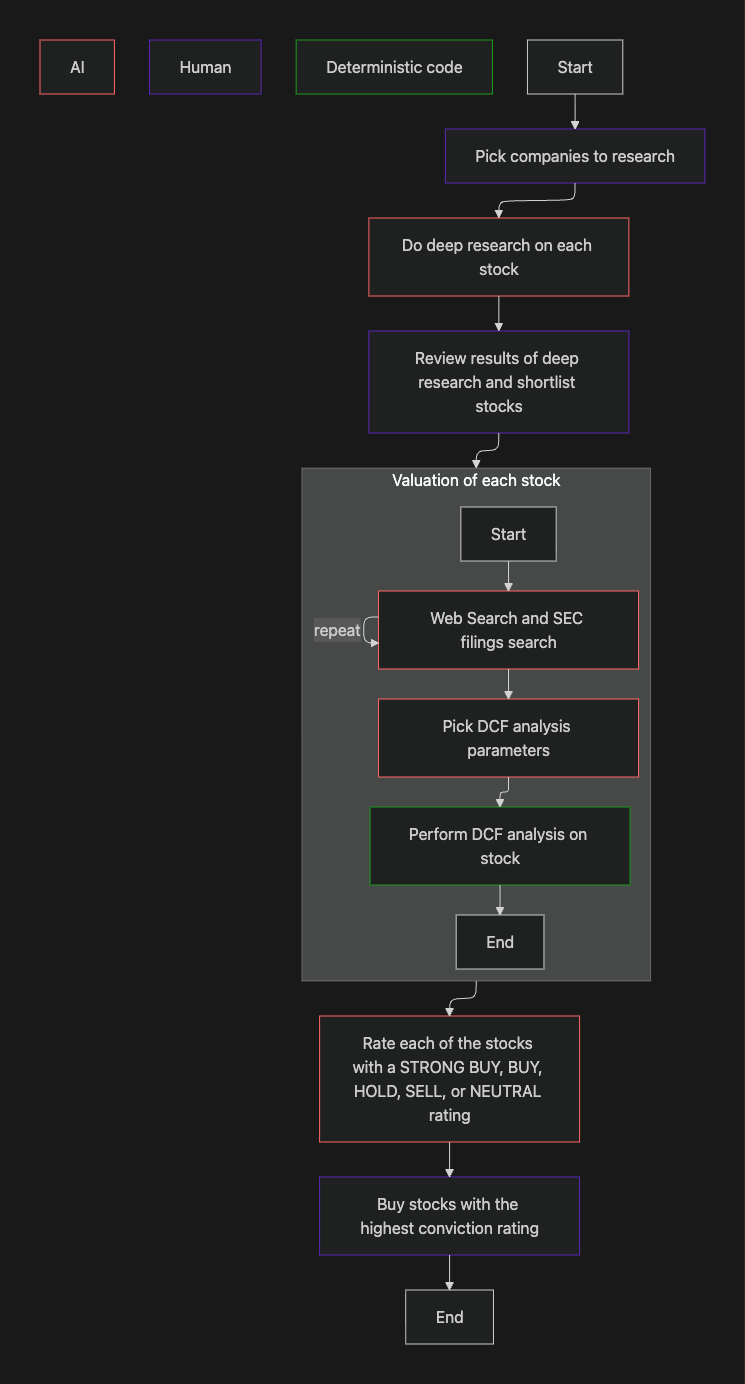
The new agentic stock-picking workflow.
More Nuanced Results
In general, as you might expect, stocks with low values given by the DCF analysis tended to be given SELL ratings and stocks with high values given by the DCF analysis tended to be given BUY ratings. Interestingly, this did not hold true for all stocks.
Despite Microsoft being reported as overvalued according to the DCF analysis, the rating AI thought that ‘[the DCF analysis] is built on demonstrably conservative assumptions,’ and decided to RATE it as a BUY.
For PayPal, the rating AI argued that the company was even more undervalued than the DCF analysis suggested as the DCF analysis hadn’t taken into account several factor. The rating AI labelled this a STRONG BUY despite only giving a BUY rating to other stocks that had even higher margins of safety.
Conclusion
In this blog, I successfully reduced the cost of my running Discount Analyst agent by a significant amount. Before this exercise, I was using Opus 4.5 with Perplexity without caching, which cost ~$0.70 per stock valuation. After this, each valuation started costing ~$0.10. Needless to say, it's a massive improvement.